Bu dönem danışmanlığını yapacağım bitirme projesi gruplarından biri twitter aktivitesinin borsadaki hareketler ile ilişkisi olup olmadığı konusunda çalışacak. Bunun için ön hazırlık yaparken, bahar dönemi kayıt zamanı Boğaziçi Üniversitesi hakkında twitterda neler yazılmış bir bakayım dedim ve sonuçlarını paylaşmak istedim. Çok detaylı bir analiz yapmadım. Biraz hızlıca oldu ama fena olmadı. Bu işleri yapmak için R (http://www.r-project.org/) kullandığımı belirterek başlayayım. Verdiğim derslerde de yoğun olarak R göstermeye çalışıyorum. Yaptığım şeye gelirsek de Pazartesi (10 Şubat 2014) ve Cuma (14 Şubat 2014) günleri arasında, içinde ‘#boun’ geçen yani boun hashtagli tivitleri incelemek oldu. Bunu yapmak için kullandığım R kodlarını da yakın zamanda paylaşacağım. Yeri gelmişken Berk Orbay’ın R ile twitter’i konuşturma ile ilgili yazısını da paylaşmak isterim -> http://berkorbay.me/r-ipuclari-3-r-ile-tweet-atmak Daha rafine bir bilgi sağlamak mümkün (bir takım temizlikler yapmak) ama işlenmemiş haliyle en çok kullanılan kelimelerin yoğunluğu şu şekilde (bu gösterime ‘wordcloud’ deniyor. Daha büyük daha çok yazıldı demek.).

Kayıt (‘registration’) ön plana çıkmış. Bir kısım insan da büyük ihtimalle ‘registrationhikayem’ hashtagiyle paylaşımlarda bulunmuş. mavibouncuk nedir bilmiyorum. Araştırmalarıma göre Boğaziçi’ne özel bir sosyal ağ olma yolunda (https://twitter.com/mavibouncuk, sitesi yapım aşamasında http://mavibouncuk.com/). Okul açılırken reklam yapmışlar gibi. ‘Consent’, ‘kota’ gibi kelimeler de arkadan geliyor. Yukarıdaki grafikte nelerin (hangi kelimelerin) birlikte görüldüğü konusunda bir bilgi yok. Bunun için de her dökümanda (tivitte) geçen kelimeleri bir-sıfır (binary) bir şekilde ifade eden ‘document-term matrix (http://en.wikipedia.org/wiki/Document-term_matrix)’ i elde ediyoruz. Sonrasında kelimeleri (term) kümeleyerek hangi kelimeler birlikte görülmüş bulabiliyoruz. Kümelemenin detaylarına girmeyeceğim. Bunu veri madenciliği ile ilgili yazdığım yazıların birinde anlatacağım. Detayları merak edenler bana ulaşırsa kısaca bahsedebilirim (kullanılan kümeleme yaklaşımı ‘hierarchical clustering’). Bunun da sonucu şöyle:
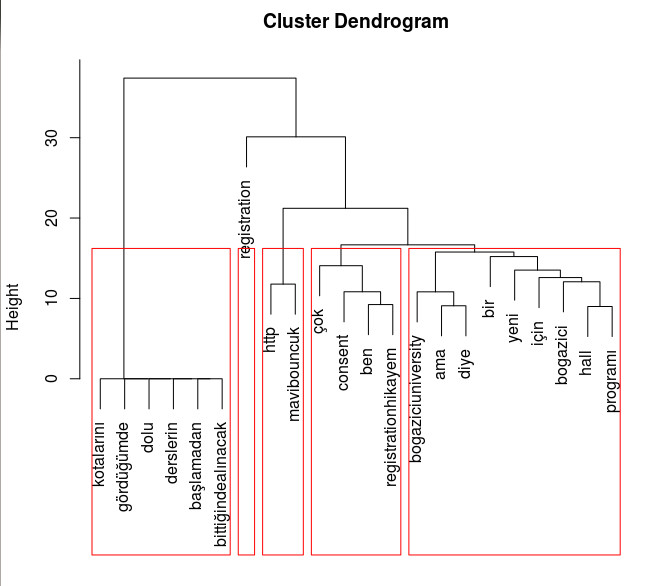
Burada belirtilen yükseklik (height) bir benzerlik ölçüsünü ifade ediyor. Aynı seviyede olanlar birbirine benzer ve yükseklik seviyesi farkları ve dallanmalar da birbirinden farklılığı ifade ediyor. Önceden de bahsettigim gibi bunun detaylarını ilerleyen zamanlarda paylaşacağım. Şimdilik bu kadarı basit tutmak adına yeter.Her bir kırmızı kutu beş kümeden birini ifade ediyor. Yani toplam beş kümemiz var. Önceden de bahsettiğim üzere normalde bu tür işler ‘stopword’ adı verilen veri madenciliği açısından anlamlı olmayacak “ben, ama, bir, diye” ve benzeri gibi ifadeler atılır ama dediğim gibi hızlıca birşeyler yaptığım için bunların bir kısmı kalmış (sağ taraftaki küme). En soldaki ilginç. Kayıt işlerine bir nevi veryansın eder gibi. ‘registrationhikayem’ hashtagi ile atılan tivitlerde bolca ‘ben’ ve ‘consent’ ifadesi kullanmış. Genel olarak öğrencilerin halini yoklamak için ilginç bir analiz olabilir. Bu kadarıyla paylaşmak istedim.