Bu seneki inet konferasında Boğaziçi End. Müh. doktora yapan Berk Orbay ve Boğaziçi Bilg. Müh. doktora yapan Uzay Çetin ile birlikte R’la ilgili bir atölye çalışması yaptık (27 Kasım 2014). Benim sunumuma aşağıdaki linkten ulaşabilirsiniz.
Bu seneki inet konferasında Boğaziçi End. Müh. doktora yapan Berk Orbay ve Boğaziçi Bilg. Müh. doktora yapan Uzay Çetin ile birlikte R’la ilgili bir atölye çalışması yaptık (27 Kasım 2014). Benim sunumuma aşağıdaki linkten ulaşabilirsiniz.
Derste göstermek üzere birkaç örnek karıştırırken önüme 2008 yılında Nature’da yayınlanmış ilginç bir makale denk geldi (linki http://www.nature.com/nature/journal/v456/n7218/full/nature07331.html).
Özetle 3000 kadar Avrupalının genetik farklılıklarını bir şekilde sayısal olarak ifade edip (p tane değişkenle ya da bir başka deyişle p uzunluğunda bir vektörle) daha sonra veri madenciliğinde veri boyutunu küçültmek (dimensionality reduction) için kullanılan klasik yöntemlerden biri olan temel bileşen analizi,TBA (principal component analysis, PCA) ile iki boyuta indirgemişler ve bunu da harita üzerinde göstermişler. Her gördüğünüz nokta bir insanı temsil ediyor ve renkler ve kısaltmalar ile ülkeler belirlenmiş.
Ülkelerin yakınlığıyla genetik benzerlik arasındaki ilişki beklendik bir çıktı aslında. Burada koordinat sistemi (temel bileşen analizi kullanılarak iki boyuta indirilmiş koordinatlardaki gösterim) haritayla benzerlik kurmak adına döndürülmuş vaziyette. Büyük noktalar örneklerin ağırlık merkezini göstermekte. O ülke icin temsilci nokta gibi düşünebilirsiniz. Türkiye’den çok fazla örnek yok maalesef. Sebebi yapılan örneklem (sampling) ile alakalı bir durum olabileceği gibi, Türklerin böyle bir bilgiyi paylaşmaması da olabilir. Bir takım bulgular tahmin edilebilecek (ya da bilinenlerle) örtüşüyor. Gözüme çarpan Slovakların İtalyanlar ile yakınlığı ama bunun sebebi de Slovak tarafında örnek sayısının az olması büyük ihtimal ile.
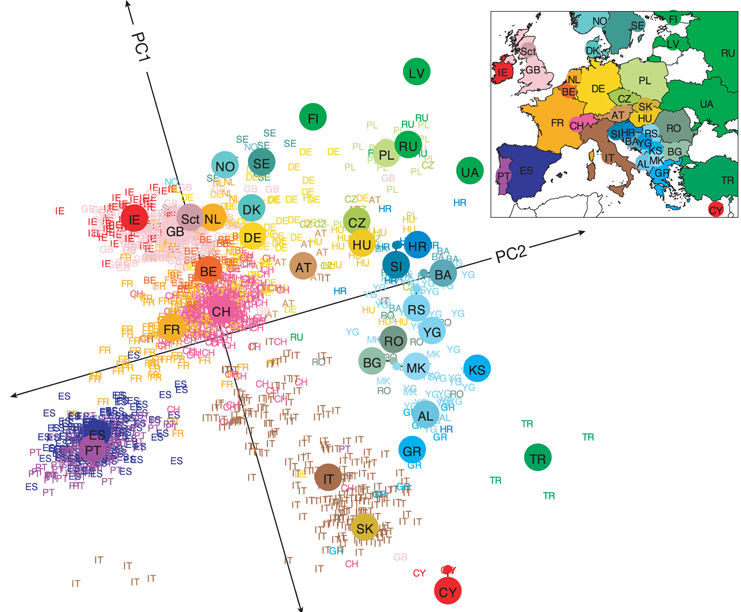
Güzel bir uygulama olmuş ve sonuçları da ilginç sayılır.
Temel Bileşen Analizi (TBA) nedir?
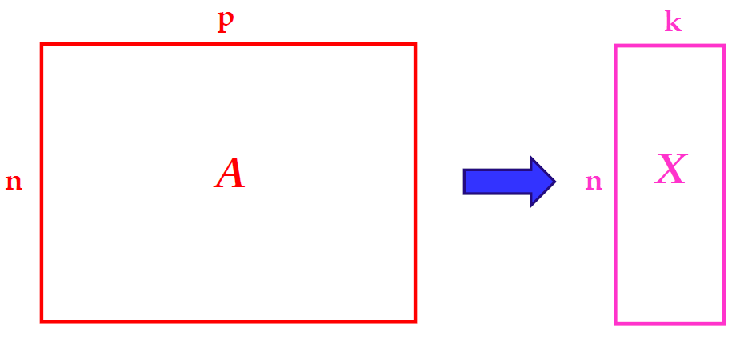
Kısaca TBA, p boyutlu bir uzaydan (verinizin p tane değişken ile ifade edildiğini düşünürseniz) k<p boyutlu bir uzaya dönüşümü sağlıyor. Şekil ile gösterecek olursak şöyle:
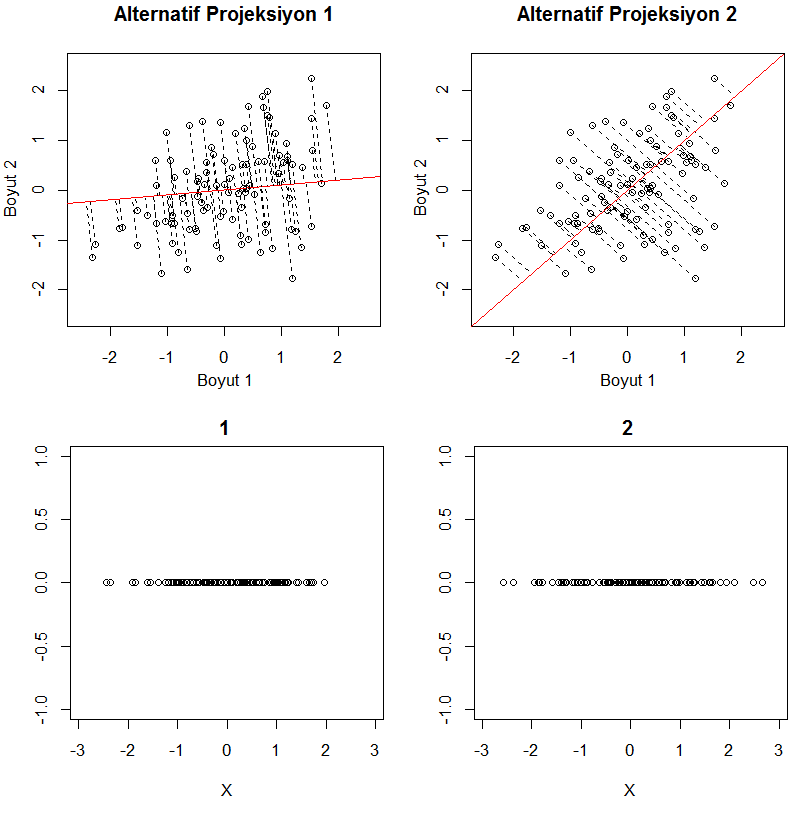
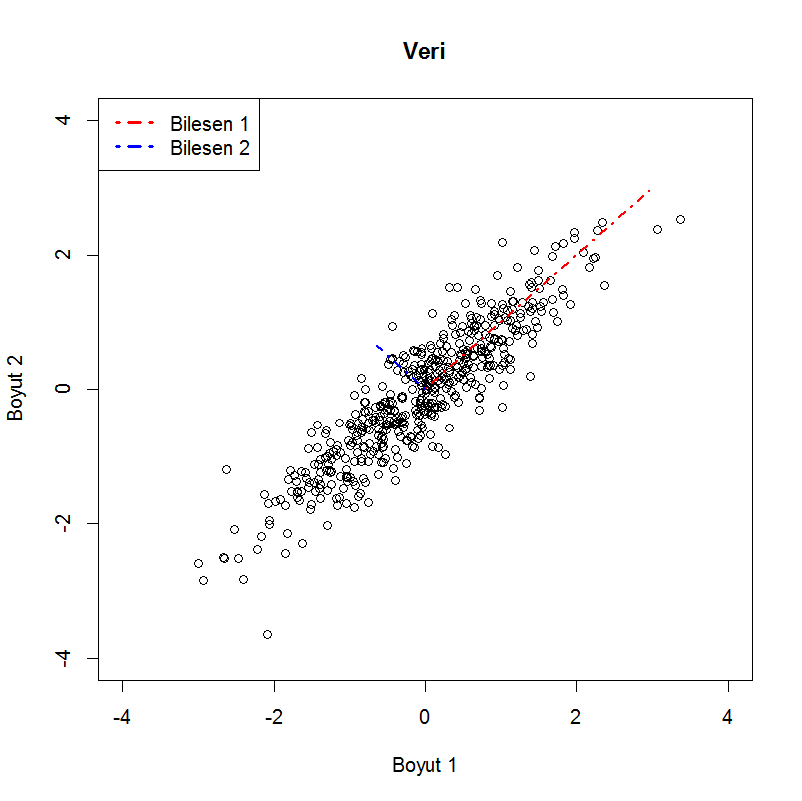
Bu küçülmeyi sağlamanın bir yolu verinizin daha küçük bir uzayda izdüşümünü (projeksiyon) almak. Aşağıda bunun geometrik olarak ne anlama geldiğini şekille anlatmaya çalıştım. Gösterim kolaylığı olması açısından 2 değişkenli 100 tane örnek içeren bir veri kullandım. Kırmızı ile gösterilen çizgi noktaların izdüşümünü alacağımız doğrular olsun. Aşağıda verinin bu doğrulardaki izdüşümünü yatay olarak döndürülmüş halini göstermeye çalıştım. Görülebileceği üzere sonsuz tane doğru üzerinde izdüşümü alabiliriz. Bu noktada hangi doğru/doğruları kullanmak en mantıklıdır sorusu akla geliyor.
Birçok veri madenciliği probleminde olduğu gibi burada da amaç en az seviyede bilgi kaybı. Eğer bilginin tanımı ne derseniz, bir bakış açısı değişkenler arası ilişkiler der (kovaryans). Kovaryans ile ilgili detaylı bilgiye http://tr.wikipedia.org/wiki/Kovaryans linkinden ulaşabilirsiniz. Amaç eldeki büyük veriyi değişkenler arası ilişkileri en iyi şekilde koruyarak daha küçük bir uzayda ifade etmeye çalışmaktan ibaret (yukarıdaki şekilde gösterildiği gibi). Bunu anlatmak için Gaussian (Normal) dağılımının geometrisinden bahsetmek istiyorum. Yine kolaylık sağlaması adına iki değişkenli (bivariate) bir Gaussian dağılım ele alalım. Gaussian dağılım olasılık yoğunluk fonksiyonu şekli itibariyle elips şeklindeki dağılımlar (http://en.wikipedia.org/wiki/Elliptical_distribution) sınıfına girer ve bu dağılımın parametreleri her değişken için ortalama ve de değişkenler arası ilişkiyi anlatan kovaryans matrisidir. Bu parametreler olasılık yoğunluk fonksiyonun şeklini (yani elipsin) şeklini belirler. Aşağıda buna bir örnek görebilirsiniz.
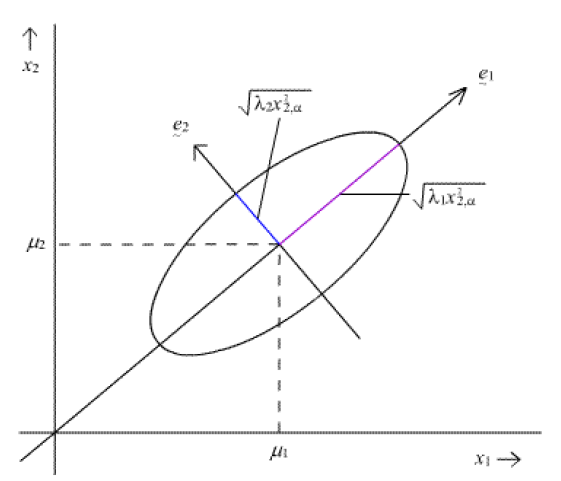
Bir şekilde değişkenler arası ilişkinin yönünü gösteren e1 ve e2 vektörleri, dağılımın parametresi olan kovaryans matrisinin özvektörleridir (eigenvector). Eğer yukarıda gösterdiğimiz projeksiyonlar ile ilişkilendirirsek, verimizin Gaussian dağıldığını varsayıp örneklerimiz üzerinden hesapladığımız kovaryans matrisinin (örnek [“sample”] kovaryansı) özvektörleri bizim için ideal projeksiyonu vermesini bekleriz. Özvektörlere ait özdeğerler (eigenvalue) ise o yöndeki ilişkinin gücünü verecektir. Bazen bu türden bir ilişkiye sinyal olarak bakıp bu yöndeki sinyallerin gücü olarak da adlandırılır. Peki neden özvektörler derseniz, özvektörlerin birbirine dik olması bir önemli özellik. Böylece projeksiyon yaptığımız zaman birbiriyle korelasyonu sıfır olan iki vektörü kullanmış oluyoruz ve bu da aynı bilgiyi tekrar kullanmamak adına önemli oluyor. Bu türden bir analizde özdeğerler verideki varyansın ne kadarını kapsadığımız hakkında bilgi verir.
Aşağıdaki şekilde de bunu görebilirsiniz. Verimiz (500 adet Gaussian dağılımdan rastgele yaratılmış nokta) x ekseninde daha uzun, yani o yöndeki ilişkiyi bir şekilde hesaba katmamız önemli. y eksenindeki nispeten bir tür gürültü etkisi var gibi. Bu veri ortalamaları 0 olan ve kovaryans matrisi [latex] \begin{array}{cc} 1 & 0.8 \\ 0.8 & 1 \end{array} [/latex] olan iki değişkenli (bivariate) Gaussian dağılımdan üretildi. TBA sonucu bulunan düzlemler (özvektörler) de özdeğerleri ile doğru orantılı olarak şekilde gösterilmiştir. Burada özdeğeri en yüksek (değişkenliğin daha büyük bir bölümünü açıklayabilen) bileşeni seçip artık 2 değişkenli noktalarımızı tek bir değerle ifade edebiliriz. Bu değer aslında çok basit anlamda birim uzunluktaki özvektör ile veri vektörünün çarpımı. Yani bir izdüşümü. Buna şöyle de bakılabilir. Öyle vektörler bulduk ki, orijinal nokta bu vektörlerin lineer kombinasyonu şeklinde ifade edilebilir. Biz de bu lineer kombinasyonun ağırlıklarını yeni veri olarak kullanabiliriz (çünkü temel (basis) vektörler sabit ve veriler katsayılar cinsinden ifade edilebilir). Bunu bir başka yazıda yüz tanıma problemi üzerinde anlatmaya çalışacağım.
Kovaryans matrisi üzerinde çalıştığımız için değişkenlerin ölçekleri önemlidir. Farklı seviyelerde değişkenler olduğunda her değişkenden (her sütun) ortalaması çıkarılıp daha sonra bu değerler standart sapmaya bölünür. Yani bir tür standardizasyon ya da normalizasyon yapmak gerekir. İkiden fazla değişkenin olduğu ve olçek farklılıkları olduğu durumda değişkenler arası ilişkilerin büyüklüğü (kovaryans matrisinin elemanları) karşılaştırılabilir olmaktan çıkar.
Modifiye edilmemiş haliyle TBA verinizin Gaussian bir dağılımdan geldiğini ve lineer ilişkileri barındırdığını varsayar. Bu varsayımları aşmak için alternatif yöntemler ve TBA üzerinde çeşitlemeler (örnegin kernel PCA) önerilmiştir. Bilgisayar bilimlerinde bunu bir tür veri sıkıştırma yöntemi olarak da anlatırlar. Çünkü p boyutundaki verinizi artık daha küçük bir uzayda (ya da daha az değişkenle) ve minimal bilgi kaybıyla ifade etmek temel amaçtır.
Bir önceki yazımda Boğaziçi Üniversitesi’nde kayıt zamanı atılmış twitter verisi üzerine yaptığım bir takım analizlerin sonuçlarını paylaşmıştım. Şimdi sıra bunların kodlarını paylaşmaya geldi. Önceki yazıda bahsettiğim gibi bu kodlar R’da yazıldı. Eğer siz de benzer kodları kullanmak istiyorsanız, R programını http://www.r-project.org/ sitesinden yüklemeniz gerekmekte.
Twitter’dan veri alabilmek için bir takım işlemler yapmanız gerekiyor. Bunlar Berk Orbay’ın şu blog yazısında mevcut. O yazıda R kullanarak nasıl tivit atabileceğiniz anlatılıyor. Bize twitter api’sine bağlanmaya kadar olan kısmı lazım diyebilirim.
Burada paylaşacağım kodlar, bir şekilde twitter api’sine bağlandığınızı varsayacak. Ayrıca bu analizler Ubuntu 13.10 işletim sisteminde yapılmıştır ve kullanılan paketlerden bir tanesi bilgisayarınıza Curl yüklenmesini gerektirmektedir. Windows’ta da benzer kodlar kullanılabilir fakat, ‘encoding’ problemleri yüzünden bir takım Türkçe karakterler ile ilgili problem yaşayabileceğinizi belirtmek isterim.
require(twitteR)
require(wordcloud)
require(tm)
require(RCurl)
require(RJSONIO)
#Twitter kayıt bilgilerinin olduğu R session verisini yükle
load("/home/baydogan/Research/Twitter/twitter_auth.Rdata")
registerTwitterOAuth(twitCred)
aranacak_ifade='#boun'
veri <- searchTwitter(aranacak_ifade, n=1500,since='2014-02-10', until='2014-02-14',retryOnRateLimit=200)
#metinleri kaydet
veri_yazilar <- sapply(veri, function(x) x$getText())
#derlemi (corpus) hazirla
veri_derlem <- Corpus(VectorSource(veri_yazilar))
#temizle
veri_derlem <- tm_map(veri_derlem, tolower)
veri_derlem <- tm_map(veri_derlem, stripWhitespace)
veri_derlem <- tm_map(veri_derlem, removePunctuation)
#kelime bulutu ciz
wordcloud(veri_derlem)
#kelimelerin hangi tivitlerde geçtiğini belirten bir/sıfır matrisi oluştur
dtm <- TermDocumentMatrix(veri_derlem)
#az geçen kelimeleri at
dtm_rem <- removeSparseTerms(dtm, sparse=0.95)
#data frame tipine dönüştür
dtm_df <- as.data.frame(inspect(dtm_rem))
#tüm sütunları aynı seviyeye çek
dtm_df_scaled <- scale(dtm_df)
#uzaklık matrisini oluştur
d <- dist(dtm_df_scaled, method = "euclidean")
#kümele
fit <- hclust(d, method="ward")
#kümeleme sonucunu çiz
plot(fit)
Kodlar ile ilgili detaylı açıklamalar çok yakında.
Bu dönem danışmanlığını yapacağım bitirme projesi gruplarından biri twitter aktivitesinin borsadaki hareketler ile ilişkisi olup olmadığı konusunda çalışacak. Bunun için ön hazırlık yaparken, bahar dönemi kayıt zamanı Boğaziçi Üniversitesi hakkında twitterda neler yazılmış bir bakayım dedim ve sonuçlarını paylaşmak istedim. Çok detaylı bir analiz yapmadım. Biraz hızlıca oldu ama fena olmadı. Bu işleri yapmak için R (http://www.r-project.org/) kullandığımı belirterek başlayayım. Verdiğim derslerde de yoğun olarak R göstermeye çalışıyorum. Yaptığım şeye gelirsek de Pazartesi (10 Şubat 2014) ve Cuma (14 Şubat 2014) günleri arasında, içinde ‘#boun’ geçen yani boun hashtagli tivitleri incelemek oldu. Bunu yapmak için kullandığım R kodlarını da yakın zamanda paylaşacağım. Yeri gelmişken Berk Orbay’ın R ile twitter’i konuşturma ile ilgili yazısını da paylaşmak isterim -> http://berkorbay.me/r-ipuclari-3-r-ile-tweet-atmak Daha rafine bir bilgi sağlamak mümkün (bir takım temizlikler yapmak) ama işlenmemiş haliyle en çok kullanılan kelimelerin yoğunluğu şu şekilde (bu gösterime ‘wordcloud’ deniyor. Daha büyük daha çok yazıldı demek.).

Kayıt (‘registration’) ön plana çıkmış. Bir kısım insan da büyük ihtimalle ‘registrationhikayem’ hashtagiyle paylaşımlarda bulunmuş. mavibouncuk nedir bilmiyorum. Araştırmalarıma göre Boğaziçi’ne özel bir sosyal ağ olma yolunda (https://twitter.com/mavibouncuk, sitesi yapım aşamasında http://mavibouncuk.com/). Okul açılırken reklam yapmışlar gibi. ‘Consent’, ‘kota’ gibi kelimeler de arkadan geliyor. Yukarıdaki grafikte nelerin (hangi kelimelerin) birlikte görüldüğü konusunda bir bilgi yok. Bunun için de her dökümanda (tivitte) geçen kelimeleri bir-sıfır (binary) bir şekilde ifade eden ‘document-term matrix (http://en.wikipedia.org/wiki/Document-term_matrix)’ i elde ediyoruz. Sonrasında kelimeleri (term) kümeleyerek hangi kelimeler birlikte görülmüş bulabiliyoruz. Kümelemenin detaylarına girmeyeceğim. Bunu veri madenciliği ile ilgili yazdığım yazıların birinde anlatacağım. Detayları merak edenler bana ulaşırsa kısaca bahsedebilirim (kullanılan kümeleme yaklaşımı ‘hierarchical clustering’). Bunun da sonucu şöyle:
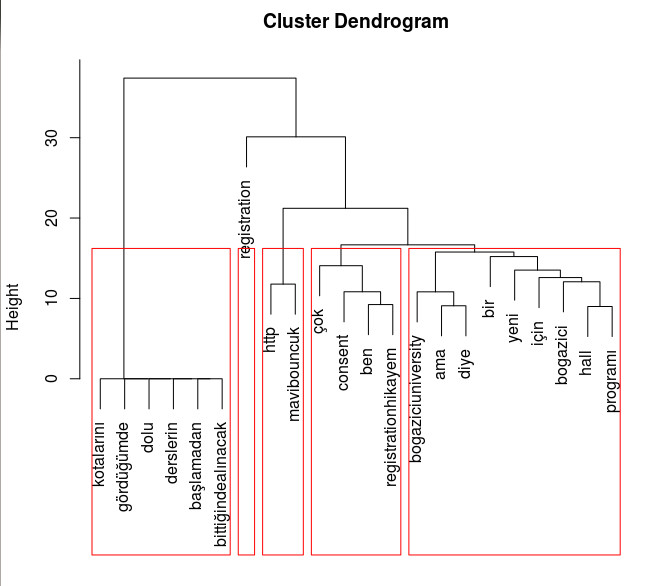
Burada belirtilen yükseklik (height) bir benzerlik ölçüsünü ifade ediyor. Aynı seviyede olanlar birbirine benzer ve yükseklik seviyesi farkları ve dallanmalar da birbirinden farklılığı ifade ediyor. Önceden de bahsettigim gibi bunun detaylarını ilerleyen zamanlarda paylaşacağım. Şimdilik bu kadarı basit tutmak adına yeter.Her bir kırmızı kutu beş kümeden birini ifade ediyor. Yani toplam beş kümemiz var. Önceden de bahsettiğim üzere normalde bu tür işler ‘stopword’ adı verilen veri madenciliği açısından anlamlı olmayacak “ben, ama, bir, diye” ve benzeri gibi ifadeler atılır ama dediğim gibi hızlıca birşeyler yaptığım için bunların bir kısmı kalmış (sağ taraftaki küme). En soldaki ilginç. Kayıt işlerine bir nevi veryansın eder gibi. ‘registrationhikayem’ hashtagi ile atılan tivitlerde bolca ‘ben’ ve ‘consent’ ifadesi kullanmış. Genel olarak öğrencilerin halini yoklamak için ilginç bir analiz olabilir. Bu kadarıyla paylaşmak istedim.
Veri madenciliği hakkında yazılar yazmaya başladım. Giriş yapmadan önce şunu belirtmek isterim. Yazılarım parça parça olacak ve öngördüğüm süre 2-3 haftalık dönemler. Ayrıca yazıdaki hedef kitlemin Endüstri Mühendisliği okumuş ya da bir şekilde istatistik işlerine bulaşmış kişiler olduğunu söylemek zorundayım. Buradaki yazılan her şey tamamıyla doğru olmayabilir. Yapmaya çalıştığım şeyi, öğrendiklerimi kendi süzgeçimden geçirdikten sonra aktarmak diye adlandıralım.
Giriş
Veri madenciliği nedir sorusuna cevap vermeden önce derslerde öğrendiğimiz (ya da öğrenemediğimiz) hipotez testlerine dayalı veri analizinden bahsetmek anlamlı olacaktır. Bunun sonraki kısımlarda işleri kolaylaştıracağını düşünüyorum.
Karşımıza çıkan birçok problemde belki bilmeden yaptığımız bir şeye açıklık getirmeye çalışacağım. Mühendislik deneylerinin tasarlanması (‘design of engineering experiments’) konusunda çalışmış/çalışan, ders almış kişiler bilirler. Bunlardaki temel amaç bir çıktıya potansiyel olarak etki ettiğini düşündüğümüz faktörlerin incelenmesidir. Aldığım bir derste yaptığım projeden örnek verecek olursam. Yoğurdun pekliği üzerine etki eden faktörleri incelemek istediğiniz bir deneyde sütün kaynamış olup olmadığı, süt sıcaklığı, maya miktarı, süt türü, bekleme süresi ve buzdolabında bekletme süresi potansiyel faktörlerdir. Bir çok evde yoğurt mayalama sürecine (proses) bilimsel açıdan yaklaşmadan istenilen düzeyde yoğurtlar yapılmaktadır (ister deneme yanılma olsun, ya da siz tecrübe deyin). Diyelim ki yukarıda bahsettiğim faktörlerin pekliğe etkisini belli güvenilirlik seviyelerinde ölçmek amacında olalım. Bunun için öncelikle faktörleri belirlememiz gerekir. Aşağıda belirtilen faktörlerin bizim için önemli olduğunu varsayalım (bir başka deyişle yoğurt mayalanmasında etkili rol oynadığını varsayalım):
Daha sonra bu faktörler için seviyeler belirlememiz gerekir ki, değişik faktör seviyelerinin yoğurt pekliği üzerine etkisini inceleyebilelim. Örneğin süt türü; yağsız, yarım yağlı ve tam yağlı olabilir. Bunlar belirlendikten sonra bizim için önemli olan çıktıyı belirlememiz gerekir. Şimdilik yoğurt pekliğini, yoğurt yapıldıktan sonra 10 dakikalık süzme sonucu çıkan şu miktarı olarak belirleyelim. Burada farklı çıktılar belirlemek mümkün.
Özetle 4 faktörümüzün farklı seviye kombinasyonlarında süzülen su miktarı elde edebiliriz. Mühendislik deneylerinde her faktör seviyesi kombinasyonu için en az bir deney yapılması beklenir. Bu deney tipine göre değişebilir ama klasik deney tasarımında durum böyledir. 4 tane faktörümüzün 2′şer seviyesi olduğunu varsayarsak (süt sıcaklığı 60 derece ve 70 derece, süt türü yarım yağlı ve tam yağlı, maya miktarı az ve çok, vs gibi), [latex]2^4=16[/latex] tane farklı seviye kombinasyonunda yoğurt yapmamız beklenir. Daha güvenilir bir sonuç elde etmek için her seviye kombinasyonunun tekrarlanması önemlidir. Her kombinasyonu da 5 kere tekrarladığımızı düşünürsek (daha fazla yapabiliyorsak çok daha iyi), bu deneyde 16×5=80 farklı yoğurt yapmamız beklenir. Eğer ilgilenirseniz 3 sene kadar önce yaptığımız deneyin sonuçlarını gönderebilirim. Bana http://mustafabaydogan.com/contact.html linkinden atacağınız mesaj ile ulaşabilirsiniz.
Çok fazla dağılmadan konuya devam edecek olursam, şimdiye kadar klasik bir deney tasarımı anlattım. Dediğim gibi bunu günlük hayatınızda birçoğunuz farklı problemler için yapıyorsunuzdur. Özetle ortaya bir hipotez attık. Bu hipotez yoğurdun pekliği belirtilen dört faktörden etkilenebilir idi. Faktör seviyelerini belirledik ve hangi seviyelerde kaç tane yoğurt yapacağımıza karar verdik. Kısacası deneyimizi tasarlamış olduk. Daha sonra deneyi yaptık ve verimizi elde ettik. Sıra geldi bu veriyi analiz etmeye. Klasik yaklaşımın aşamalarını aşağıdaki şekilde de göstermeye çalıştım.

Aranızdan ANOVA’yı yani ‘Analysis of Variance’ yani Varyans Analizi’ni duymayanınız yoktur diye düşünüyorum (İstatistik ya da Kalite derslerinden). En kötü ihtimal t-testi ve F-testini istatistik derslerinde görmekteyiz. Temel amaç faktörlerin çıktıya olan etkisinin önemini ölçmektir. Bu türden bir yaklaşım ile faktörlerin yoğurt pekliğine etkisini analiz edebiliriz. Bunun detaylarına girmeyeceğim.
Gel gelelim veri madenciliğine. Çok klasik bir giriş olacak ama günümüzde toplanan verinin hacmi inanılmaz seviyelerde. Bankalar, hastaneler, telekomünikasyon kurumları vs. topladığı verinin günlük hızı belki terabaytlar seviyesinde ve takdir edersiniz ki bu veriler belirlenen bir hipoteze dayalı olarak tasarlanmış bir deneyle toplanmıyor (genellikle böyle, deney tasarımı yapılarak da toplanan veriler mevcut). İşte veri madenciliği burada devreye giriyor. Şekille başladık şekille devam edelim. Bunu da aşağıdaki şekille özetleyebiliriz.
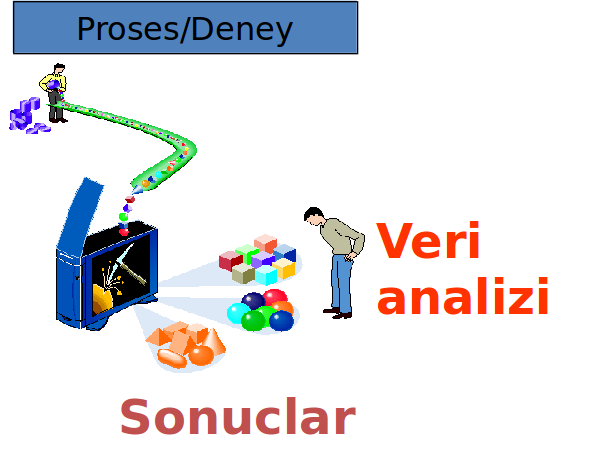
Yani ortada bir süreç (proses) veya deney var ve bu size devamlı bir veri üretmekte. Süreçlerden toplanan verilerin analizinde veri madenciliği yöntemleri genel itibariyle önden atılmış bir hipoteze dayanarak yola çıkmaz. Toplanmış/toplanan bir veri üzerinden anlamlı bir bilgi/özet çıkarabilir miyiz sorusunu cevaplamaya çalışır. Bu sıralar çokça karşıma çıkan bir problem için örnek verecek olursam.
Bir şirket müşterilerinin şirketle ilişkisini kesip kesmeyeceğini (müşteri kaybı ve ingilizce olarak ‘customer churn’ deniyor buna) tahmin etmeye çalışıyor. Müşteriler hakkında sürekli bir bilgi toplanması var. Çok klasik olarak müşterinin demografik bilgisini biliyoruz. (Yaş, nerede yaşadığı vs.). Geçmişe dönük kaç yıldır müşteri olduğu ve hangi tür paketlere üyeliği olduğunu biliyoruz. Daha ileriye gidelim. Müşterilerin çağrı merkezi kayıtları var. Yani çağrı merkezini kaç kere aradığı, aramaların kaç dakika sürdüğü gibi bilgiler mevcut. Daha da ileri gidersek müşteri ses kayıtlarını bir takım araçlar ile işleyip (ses işleme araçları) müşterinin sesinin yüksekliği bilgisini de kullanalım (niye? Çünkü yüksek ses kızgınlığın bir ifadesi olabilir ve bu da müşteri kaybına işaret edebilir). Kısacası çoğu zaman çıktıdan bağımsız (ya da klasik anlamda hipotezimizden bağımsız) bir sürü veri toplanmakta. Bu veri sadece ham haliyle değil (yaş ve yaşanılan şehir direk olarak girdi olabilir), işlenmiş bir biçimde kullanılabilmekte. Ses işleme örneğinde olduğu gibi ham veriyi kullanmayıp ham veriyi işleyip elde edeceğimiz ses yüksekliğini bir oznitelik olarak düşünebilirsiniz (evet ingilizcesi ‘feature’ olan bu ifade Türkçe’ye oznitelik diye çevrilmiş).
Müşteriden bağımsız olarak şirketin genel durumu da bu tür bir tahminde önemlidir. Yani şirket hakkında söylentiler çıktığı bir ortamda, normal zamanda müşteri kaybına neden olmayacak bir faktör, artık kayba neden olabilir. Şirketin genel şikayet durumunu şikayetvar gibi sitelerden takip edebiliriz. Ya da twitterdan şirkete yazılan twitleri kullanabiliriz. Özetle veri madenciliği yöntemleri birçok kaynaktan gelen veriyi kullanarak, hangi müşterinin ayrılma potansiyeli olduğunu tahmin etmek için yoğun olarak kullanılmakta. Eğer bunun klasik yöntem ile ilişkisini düşünecek olursak, aslında yaş, nerede yaşadığı, çağrı merkezini kaç kere aradığı gibi verileri faktörler olarak düşünüp, müşterinin ayrılmış olması ya da olmamasını da çıktı olarak düşünebilirsiniz. Yani faktörlerin müşteri kaybı üzerine etkilerini incelemek temel amaç. Tek fark ortada kontrollü bir deney yok ve aslında yapması zor. İki yaklaşımın benzerliklerini/farklılıklarını göstermek adına bahsetmek istedim. Diyebilirsiniz ki niye klasik yöntemler kullanılmıyor o durumda. Temel sebep klasik yöntemlerin varsayım problemleri. Günümüzde toplanan veri oldukça kirli ve klasik yöntemlerin gerektirdiği varsayımları sağlamıyor. Böyle durumlarda veri madenciliği yöntemleri gürbüz (‘robust’) çözümler üretebilmekte.
Bir dahaki yazıda yukarıda bahsettiğim örnek üzerinden (‘müşteri kaybı’), veri madenciliği yaklaşımlarını anlatmaya devam edeceğim.